- Sort Score
- Result 10 results
- Languages All
Results 1 - 7 of 7 for own (0.15 sec)
-
LICENSE
do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications andPlain Text - Registered: Tue May 07 12:40:20 GMT 2024 - Last Modified: Mon Nov 29 17:31:56 GMT 2021 - 13.3K bytes - Viewed (0) -
tensorflow/c/eager/c_api_unified_experimental_test.cc
TF_AbstractFunction* func = TF_FinalizeFunction(graph_ctx, add_outputs, status.get()); ASSERT_EQ(TF_OK, TF_GetCode(status.get())) << TF_Message(status.get()); // Note: TF_OutputList does not own the underlying AbstractTensors, those // need to be deleted explicitly. TF_DeleteAbstractTensor(TF_OutputListGet(add_outputs, 0)); // Build eager context. TFE_ContextOptions* opts = TFE_NewContextOptions();C++ - Registered: Tue Apr 30 12:39:09 GMT 2024 - Last Modified: Fri May 19 21:44:52 GMT 2023 - 39.1K bytes - Viewed (0) -
CONTRIBUTING.md
- Changes are consistent with the [Coding Style](#c-coding-style). - Run the [unit tests](#running-unit-tests). ## How to become a contributor and submit your own code 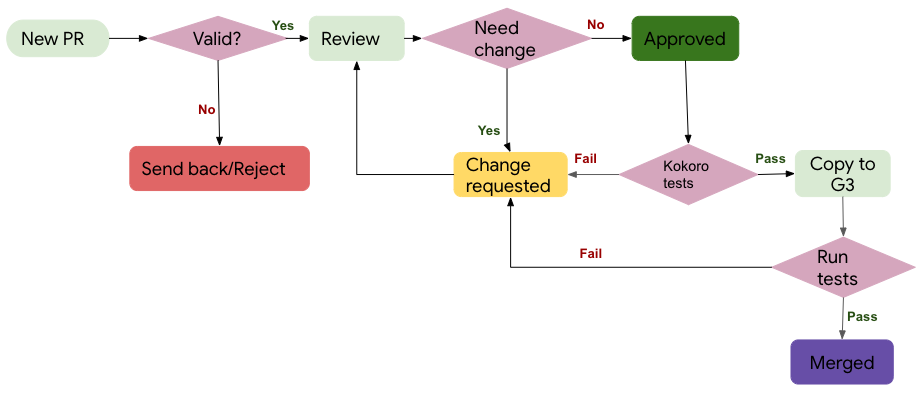 ### Typical Pull Request Workflow - **1. New PR**
Plain Text - Registered: Tue May 07 12:40:20 GMT 2024 - Last Modified: Thu Mar 21 11:45:51 GMT 2024 - 15.6K bytes - Viewed (0) -
ci/official/containers/linux_arm64/devel.usertools/code_check_full.bats
} # It's unclear why, but running this on //tensorflow/... is faster than running # only on affected targets, usually. There are targets in //tensorflow/lite that # don't pass --nobuild, so they're on their own. # # Although buildifier checks for formatting as well, "bazel build nobuild" # checks for cross-file issues like bad includes or missing BUILD definitions. #
Plain Text - Registered: Tue May 07 12:40:20 GMT 2024 - Last Modified: Mon Sep 18 14:52:45 GMT 2023 - 12.7K bytes - Viewed (0) -
ci/official/utilities/code_check_full.bats
} # It's unclear why, but running this on //tensorflow/... is faster than running # only on affected targets, usually. There are targets in //tensorflow/lite that # don't pass --nobuild, so they're on their own. # # Although buildifier checks for formatting as well, "bazel build nobuild" # checks for cross-file issues like bad includes or missing BUILD definitions. #
Plain Text - Registered: Tue Apr 30 12:39:09 GMT 2024 - Last Modified: Wed Mar 06 21:54:13 GMT 2024 - 13.2K bytes - Viewed (0) -
tensorflow/c/eager/tape.h
// // Allows an accumulator which is currently processing an operation to // temporarily reset its state. Without pushing and popping, accumulators // ignore operations executed as a direct result of their own jvp // computations. void PushState() { call_state_.emplace(nullptr, false); } void PopState() { call_state_.pop(); } private: // Helper for Accumulate: uses a GradientTape to compute forward gradients
C - Registered: Tue Apr 30 12:39:09 GMT 2024 - Last Modified: Tue Apr 02 12:40:29 GMT 2024 - 47.2K bytes - Viewed (1) -
tensorflow/c/eager/parallel_device/parallel_device.cc
using MaybeParallelTensorOwned = absl::variant<std::unique_ptr<ParallelTensor>, TensorHandlePtr>; using MaybeParallelTensorUnowned = absl::variant<ParallelTensor*, TFE_TensorHandle*>; // A ParallelDevice on its own is not registered with a TFE_Context, and so has // no device name (e.g. for `tf.device`). `NamedParallelDevice` associates a // name with it, which lets us pack its `ParallelTensor`s into TFE_TensorHandlesC++ - Registered: Tue Apr 30 12:39:09 GMT 2024 - Last Modified: Wed Mar 29 22:05:31 GMT 2023 - 18.3K bytes - Viewed (0)