- Sort Score
- Result 10 results
- Languages All
Results 1 - 4 of 4 for Writer (0.22 sec)
-
docs/bucket/quota/README.md
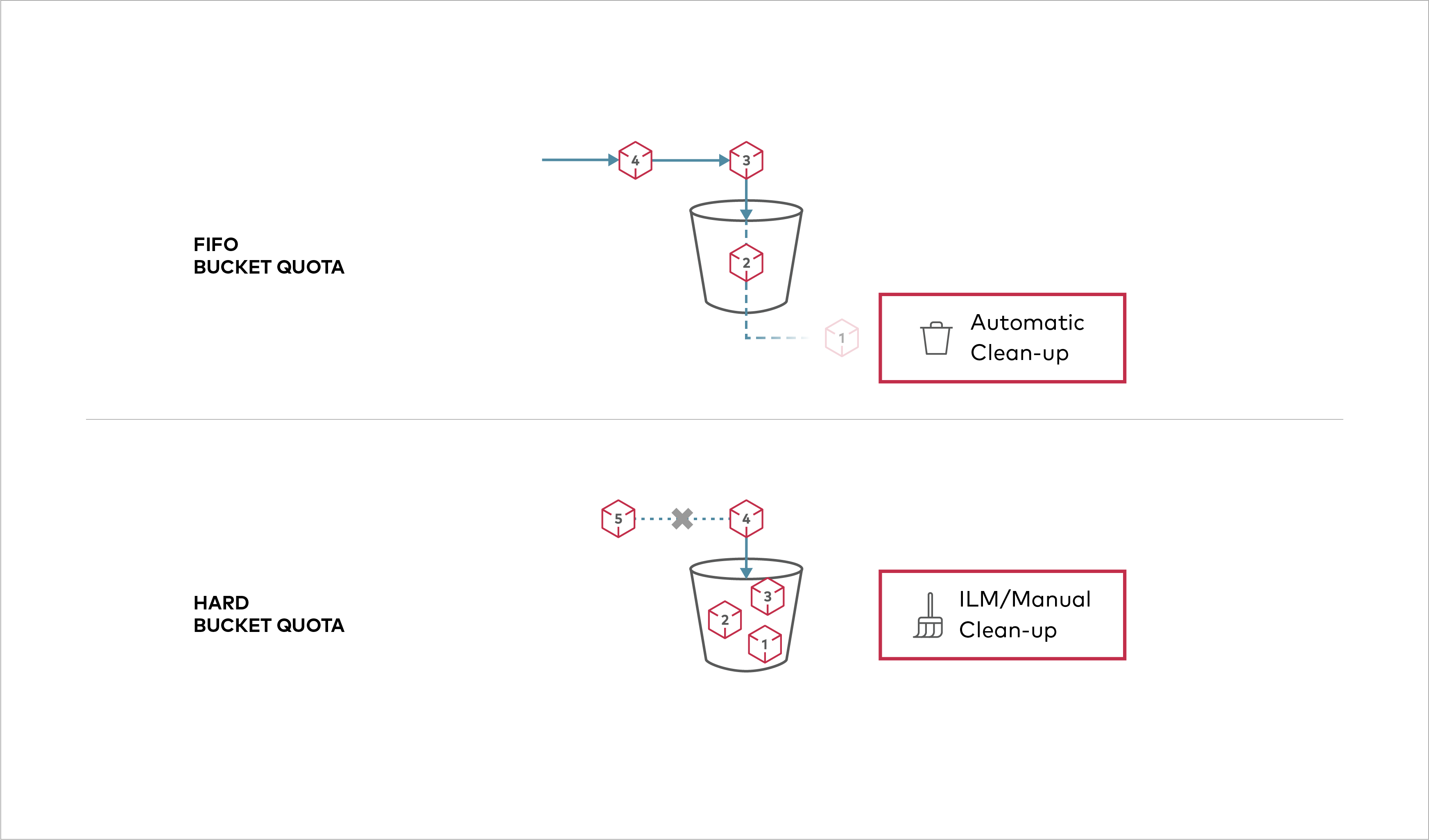 Buckets can be configured to have `Hard` quota - it disallows writes to the bucket after configured quota limit is reached. ## Prerequisites - Install MinIO - [MinIO Quickstart Guide](https://min.io/docs/minio/linux/index.html#procedure).
Plain Text - Registered: Sun Apr 21 19:28:08 GMT 2024 - Last Modified: Tue Oct 25 00:44:15 GMT 2022 - 1.1K bytes - Viewed (0) -
docs/config/README.md
delete_cleanup_interval (duration) set to change intervals when deleted objects are permanently deleted from ".trash" folder (default: '5m') odirect (boolean) set to enable or disable O_DIRECT for read and writes under special conditions. NOTE: do not disable O_DIRECT without prior testing (default: 'on') root_access (boolean) turn 'off' root credential access for all API calls including s3, admin operations (default: 'on')
Plain Text - Registered: Sun Apr 21 19:28:08 GMT 2024 - Last Modified: Mon Sep 11 21:48:54 GMT 2023 - 17.7K bytes - Viewed (0) -
docs/docker/README.md
The command creates a new local directory `~/minio/data` in your user home directory. It then starts the MinIO container with the `-v` argument to map the local path (`~/minio/data`) to the specified virtual container directory (`/data`). When MinIO writes data to `/data`, that data is actually written to the local path `~/minio/data` where it can persist between container restarts. ### Windows ```sh docker run \ -p 9000:9000 \ -p 9001:9001 \ --name minio1 \
Plain Text - Registered: Sun Apr 21 19:28:08 GMT 2024 - Last Modified: Thu Sep 29 04:28:45 GMT 2022 - 8.2K bytes - Viewed (0) -
docs/bigdata/README.md
- Run the Apache Spark Pi job in yarn-client mode, using code from **org.apache.spark**: ``` ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn-client \ --num-executors 1 \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ examples/jars/spark-examples*.jar 10 ``` The job should produce an output as shown below. Note the value of pi in the output. ```Plain Text - Registered: Sun Apr 21 19:28:08 GMT 2024 - Last Modified: Thu Sep 29 04:28:45 GMT 2022 - 14.7K bytes - Viewed (0)